
C/C++属于编译型语言,直接编译成机器能够执行的二进制代码,效率高,难以跨平台(具体的说是难以跨CPU)执行;php/python/perl属于解释型语言,通过解释器去编译成二进制代码,因此php是可移植的,但效率相对慢;Java语言走一条中间路线,也将代码进行编译,不过是编译成Java字节码,在JVM虚拟机上执行,同样达到了跨平台的效果。所以JVM成为了Java程序运行以及执行效率的核心。
只有了解内存分配,才能对语言和程序有更深层的认识,因此我们需要花足够多的时间去研究JVM。
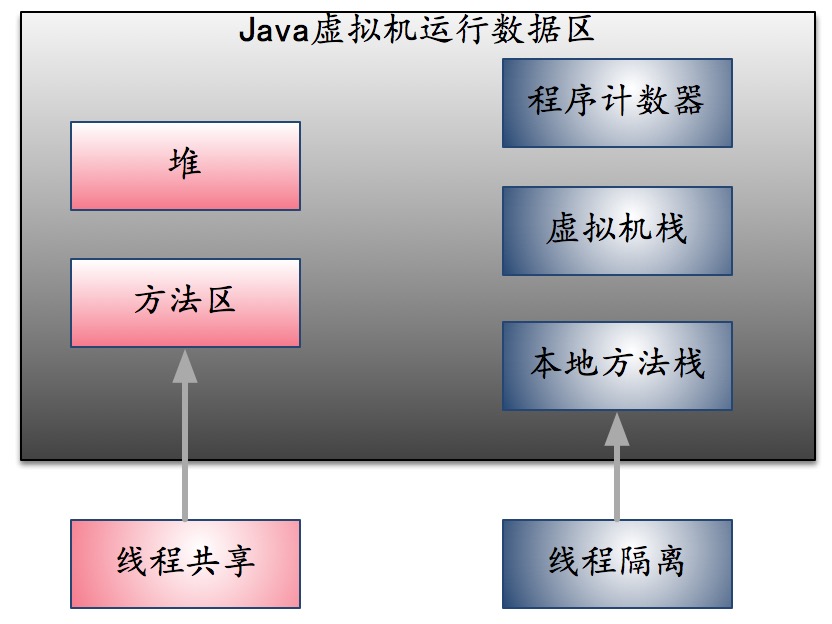
一、JVM的数据区及其用途
程序计数器(Program Counter Register):记录字节码解释器工作的位置。因此,当解释器执行分支、循环等基础指令操作都需要依赖它来记录。
虚拟机栈(VM Stack):用于存放局部变量等。
本地方法栈(Natvie Method Stack):和虚拟机栈类似,服务于Native方法。
堆(Heap):主要用于存放new的实例对象。
方法区(Method Area):用于存放虚拟机加载的静态变量、常量、编译后的代码数据等。
通过这些数据区的用途,我们可以发现,堆和方法区应该属于线程共享的。分区图如下所示:
二、延伸思考
现在的企业面试都会或多或少对JVM运行的数据区有一定的涉及,被最平常问到的问题就是JVM内存分哪几块区域?个人觉得这种问法已经过时了,参加面试的同学一定早就将这些内容背下来了。
只有更灵活的考察才能知道面试者是否真的理解了,例如可以这样问:
1、如何证明堆中存储的是对象实例?
2、写一段代码,达到栈溢出的效果(StackOverflowError)?